Secure your code from the start with the fastest and most accurate AI-powered appsec tool available. Then get back to work building great apps.
Try it for free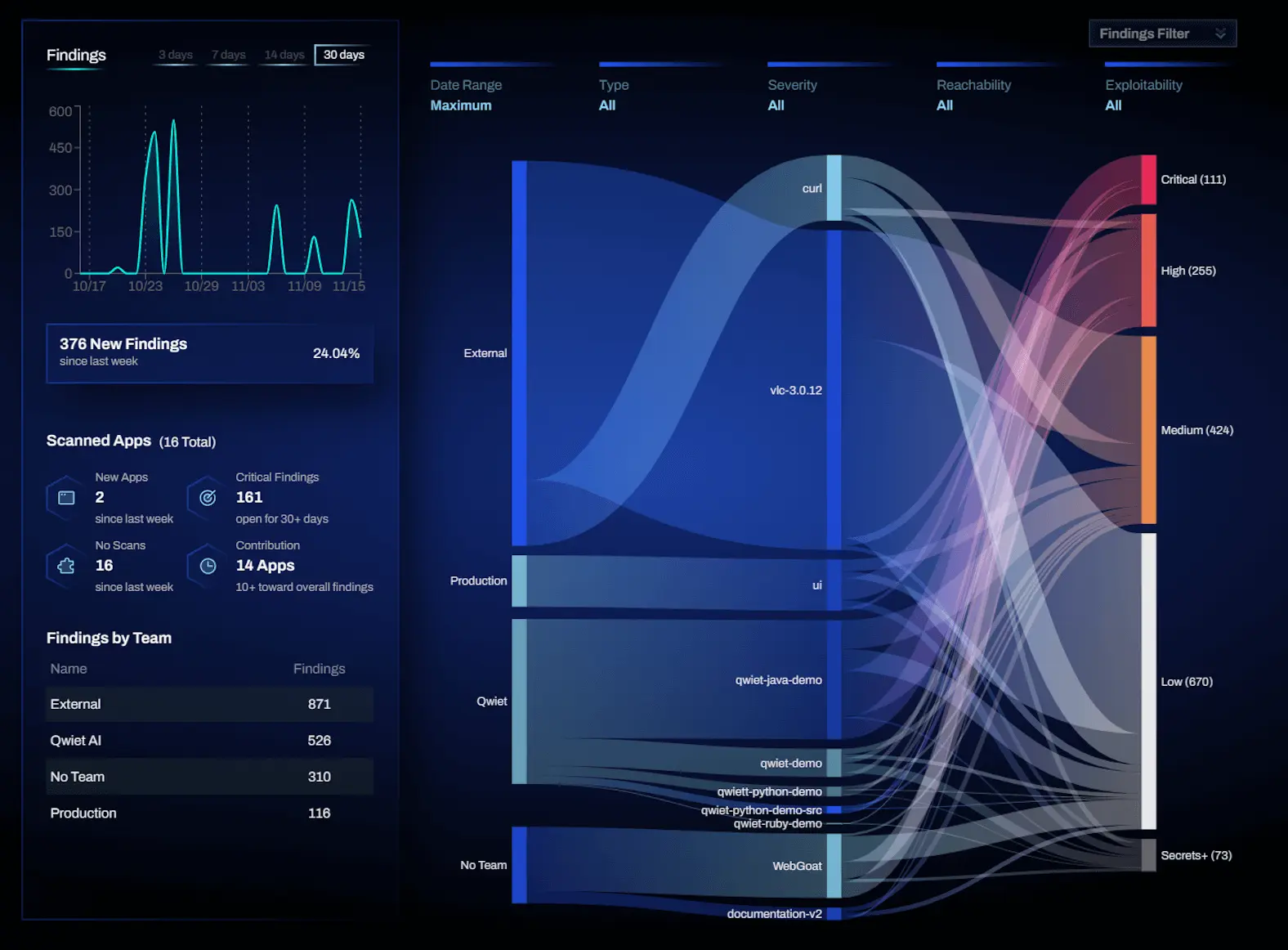






Find critical, reachable, and exploitable vulnerabilities across all your OSS libraries
April 22, 2024 | 6 min
Love them or hate them, large language models (LLM) are here to stay. After opening the Pandora’s Box of ChatGPT in late 2022, everyone from developers to grandmas began using the tool to get the answers they wanted – and fast. As with every other new technology, ChatGPT created a new set of security risks, […]
Read more

April 17, 2024 | 5 min
Imagine yourself standing in a local fair at night. The bright lights from the games beckon you, and you see your favorite game, the one you’re best at – Whack-A-Mole. You excitedly walk up to the booth, plunk down your few dollars, and get ready to whack a bunch of plastic, animatronic moles back into […]
Read more
April 9, 2024 | 7 min
Introduction In the world of software development, managing dependencies is like keeping the gears of a well-oiled machine running smoothly. Get ready to dive deep into practical strategies and tools that streamline your development process, ensuring your projects are as efficient and error-free as possible. This is your guide to mastering dependency management, making every […]
Read more
April 9, 2024 | 8 min
Introduction Have you ever wondered why meticulously coded applications sometimes falter or how the unseen processes within can impact user experience? This article dives into error handling and logging—essential practices that ensure software resilience, security, and maintainability. You’ll learn the significance of these components, understand their implementation, and discover tools that fortify application development. What […]
Read more